
容器技术系列分享(三)
Docker 进阶
目录
- Docker Image
- Docker Network
- Docker Volume
- Docker Process
- Docker security
Docker Image
Docker镜像应该是小而快的。假设你在BusyBox镜像中预编译Go二进制文件,他们就会变得又大又复杂。如果不能构建一个良好的Dockerfile来帮助你提高构建缓存命中率,那么你的镜像构建过程将会变得相当的缓慢。
比如一个用于软件安装的bash脚本,里面堆砌着大量的curl、wget等命令语句,大家在写Dockerfile的时候通常就会像写这个bash脚本一样,将一系列的Docker命令堆砌在其中,这种Dockerfile在构建镜像的时候是比较低效和缓慢的。
秩序
有频率的改变Dockerfile中命令的排序,观察分析运行命令所耗费的时间及与其他镜像共享资源的方式。
比如像WORKDIR、CMD、ENV这些命令应该在底部,而RUN apt-get -y update更新应该在上面,因为它需要更长时间来运行,也可以与所有的镜像共享。
任何ADD(或其它缓存失效的命令)命令应该尽可能地在Dockerfile底部,在那里可以做出很多改变,且后续命令缓存失效。
合适的基础镜像
比如Ruby2运行Ruby应用程序,Python3运行Python应用程序,但这两个镜像使用不同的基础镜像,所以你需要下载和构建不同的基础镜像。然而,如果使用Ubuntu运行这两个程序,就只需要下载一次基础镜像。
优化层级
在一个Dockerfile中每个命令都会在原来的基础上生成一层镜像,你可以使用三十多层命令,也可以通过组合RUN命令,并使用一行EXPOSE命令列出所有的开放端口,这样可以有效减少镜像的层数。
通过将RUN命令分组,可以在容器间分享更多的层。当然如果有一组命令可以多个容器通用,那么应该创建一个独立的基础镜像,它包含所建立的所有镜像。
对于每一层来说你都可以跨多个镜像分享,这样可以节省大量的磁盘空间。
容器体积
在创建容器并考虑到体积问题的时候,不要为了节省空间去使用体积小的镜像,尽量使用要提供数据的应用程序打成的镜像,这样对实际应用程序的调试非常有用。
消耗
当你已经构建了一个镜像,在运行它的时候发现有一个package缺少了,把它添加到Dockerfile的底部,而不是添加到顶部的run apt-get命令那里。这意味着你能尽快的重新构建这个镜像。一旦你的镜像可以正常工作,你可以再提交重新优化整理过 Dockerfile。
案例
|
|
案例分析
Common Header/Packages
这是最常见的共享层,在同一个主机上运行所有镜像应该从它开始。可以看到这里添加了一些诸如curl和git的操作,他们不是必须的,但是对调试很有用,而且因为他们在分享层,所以不会占用太多空间。
Python
Apache
2-3是语言规范层。这里的python和apache,把谁放在前面并没有硬性规定,主要看业务契合度。
Apache Envs
在Apache安装好之后直接配置环境依赖,以便于其他镜像构建时尽量多应用缓存。
Graphite and Deps
这里包含一些特定的apt和pip资源包,利用&&符号连接多个单一命令能减少镜像层级数量。
Other
这部分配置镜像本身的属性,如端口映射、目录挂载等。
First ADD
最后,将需要的应用程序打包进镜像。
Final setup
容器的启动命令。
Docker Network
Docker 网络为容器安全提供了隔离,不同的网络方案在效率和复杂度上也有区别,选择一个最合适的网络方案对应用性能和后期维护成本都有至关重要的影响。
默认网络(Default Networks)
当你安装好Docker后,它会自动创建三个网络,你可以使用docker network ls命令列举它们:

- bridge 网络
Docker安装好后都会提供默认的bridge网络即docker0网络。如果不指定docker run --net=<network>的话,Docker daemon会默认将容器连接到这个网络。在宿主机中可以看到这个网络。
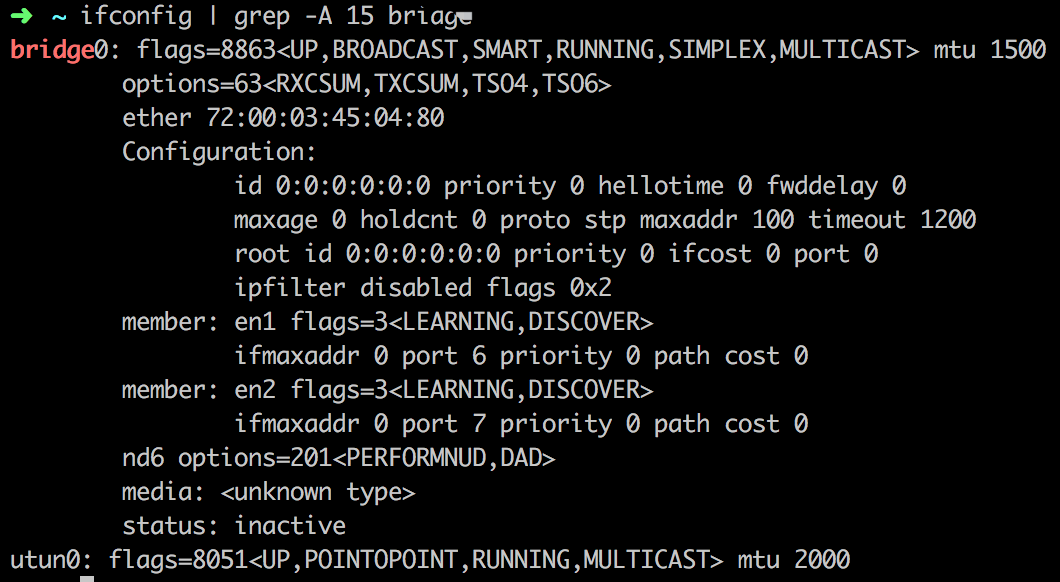
- none 网络
none 网络会添加容器到一个容器自己的网络栈,但是并没有网络接口。
- host 网络
host 网络添加一个容器到宿主机的网络栈中,你会发现容器中的网络配置和宿主机一样。
自定义网络(User-defined networks)
除了Docker提供的默认网络,用户还可以创建自定义网络以便提供更好的容器网络隔离,Docker为创建自定义网络提供了一些默认的 network driver。你可以创建一个新的 bridge network 或者 overlay network,也可以创建一个network plugin或者remote network。
用户也可以创建多个网络,把容器连接到不止一个网络中。容器仅可以同网络内的容器进行通信而不能跨网络通信。
- 自定义bridge网络
最简单的用户自定义网络就是创建一个bridge网络。
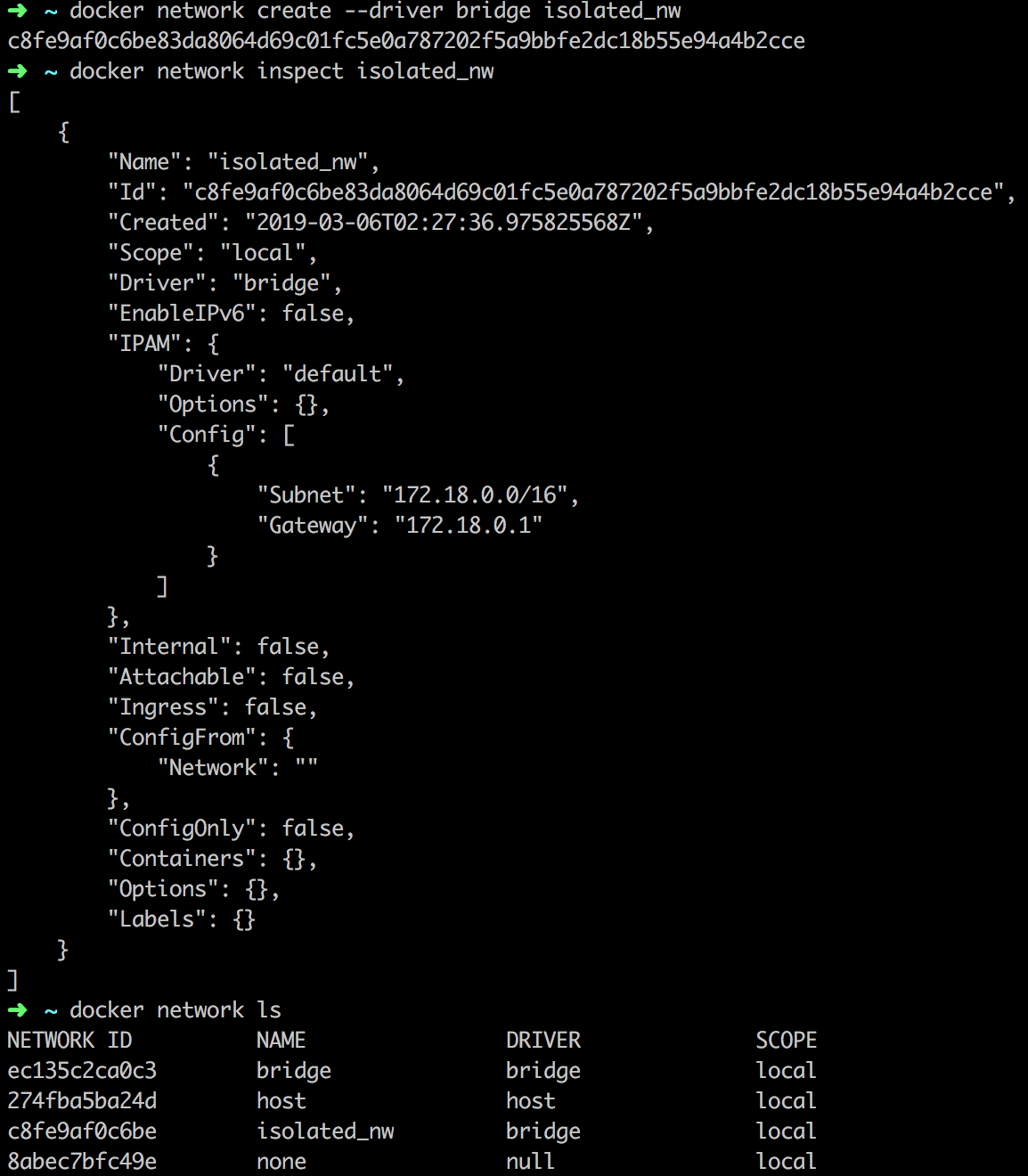
创建完之后,就可以指定新创建的容器运行在这个网络上。
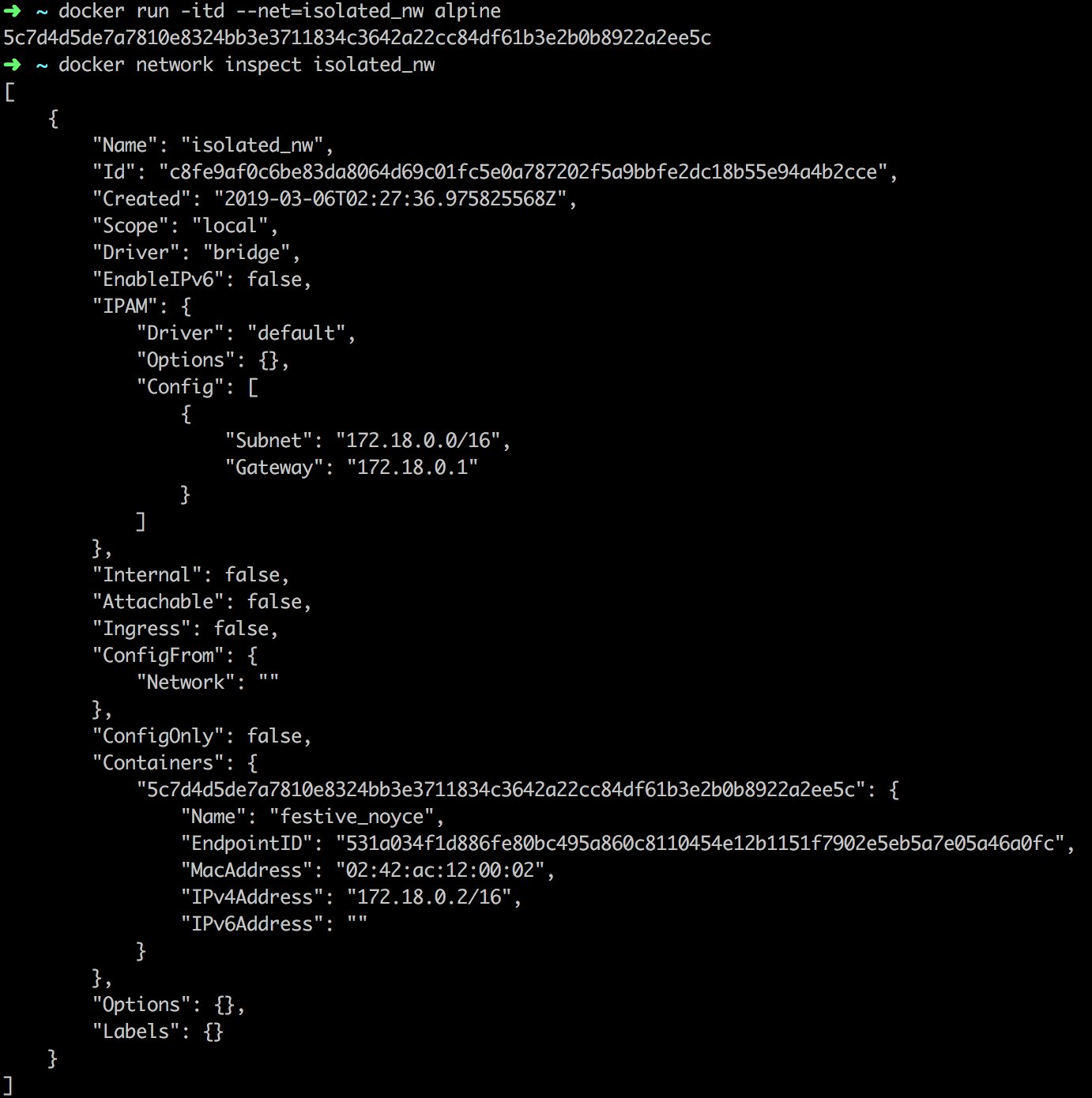
overlay网络(An overlay network)
Docker的overlay网络驱动提供原生开箱即用(out-of-the-box)的跨主机网络。完成这个支持是基于 libnetwork 和 libkv,libnetwork是一个内置基于VXLAN overlay网络驱动的一个库。
overlay网络需要一个可用的key-value存储服务,目前Docker的libkv支持Consul、Etcd、Zookeeper。
overlay网络方案对比
| Flannel | Calico | macvlan | Open vSwitch | route | |
|---|---|---|---|---|---|
| 方案特性 | 通过虚拟设备flannel0实现对docker0的管理 | 基于BGP协议的纯三层网路方案 | 基于Linux Kernel的macvlan技术 | 基于隧道的虚拟路由器技术 | 基于Linux Kernel的vRoute技术 |
| 网络要求 | 三层互通 | 三层互通 | 二层互通 | 三层互通 | 二层互通 |
| 配置难度 | 简单,基于Etcd。 | 简单,基于Etcd。 | 简单,直接使用宿主机网络,需要仔细规划IP范围。 | 复杂,需要手工配置各节点的bridge。 | 简单,使用宿主机vRoute功能,需要仔细规划每个Node的IP地址范围。 |
| 网络性能 | host-gw>VXLAN>UDP | BGP模式性能损失小,IPIP模式较小 | 性能损失可忽略 | 性能损失较小 | 性能损失小 |
| 网络限制 | 无 | 在不支持BGP协议的网络下无法使用 | 基于macvlan的容器无法与宿主机网络通信 | 无 | 在无法实现大二层互通的网络环境下无法使用 |
自定义网络插件(Custom network plugin)
你可以编写自己的网络驱动,驱动是和Docker daemon运行在同一台主机上的一个进程,并且由Docker plugin系统调用和使用。
网络插件和其他的Docker插件一样受到一些限制和安装规则。所有的插件使用Plugin API,有自己的生命周期,包含:安装、启动、停止、激活。
自定义的网络驱动安装好后,可以像使用内置的网络驱动一样使用它,例如:
docker network create --driver weave mynet
Docker内置DNS服务器(Embedded DNS Server)
Docker daemon会为每个连接到自定义网络的容器运行一个内置的DNS服务提供自动的服务发现。域名解析的请求会首先被内置的DNS服务器拦截,如果内置的DNS服务器不能解析这个请求,它才会被转发到外部的容器配置的DNS服务器。基于这个机制,容器的resolv.conf文件会将DNS服务器配置为127.0.0.1,即内置DNS服务器监听的地址。
Docker Volume

Volume数据卷是Docker的一个重要概念。数据卷是可供一个或多个容器使用的特殊目录,可以为容器应用存储提供有价值的特性:
- 持久化数据与容器的生命周期解耦:在容器删除之后数据卷中的内容可以保持。Docker 1.9之后引进的named volume可以更加方便地管理数据卷的生命周期,数据卷可以被独立地创建和删除。
- 数据卷可以用于实现容器之间的数据共享
- 可以支持不同类型的数据存储实现
Docker缺省提供了对宿主机本地文件卷的支持,可以将宿主机的目录挂载到容器之中。由于没有容器分层文件系统带来的性能损失,本地文件卷非常适合一些需要高性能数据访问的场景,比如MySQL的数据库文件存储。
同时Docker支持通过volume plugin实现不同类型的数据卷,可以更加灵活解决不同应用负载的存储需求。
但是Docker数据卷的权限管理经常令人困惑,后面就结合实例介绍Docker数据卷权限管理中的常见问题和解决方法。
从Jenkins挂载本地数据卷错误谈起
首先,我们使用Jenkins官方镜像启动一个容器,并检查日志。
可以发现容器日志一切正常。
|
|
但是,为了持久化Jenkins的数据,当我们把宿主机目录挂载到容器中时,问题出现了:
|
|
错误日志如下:

不映射本地数据卷时,查看jenkins容器的当前用户是jenkins,且”/var/jenkins_home”目录权限归属于jenkins用户。

而映射本地数据卷时,”/var/jenkins_home”目录的拥有者变成了root用户。

这就解释了为什么当jenkins用户的进程访问“/var/jenkins_home“时,会出现Permission denied的问题。
我们再检查一下宿主机上的数据卷目录,当前路径下“data”目录的拥有者是root,这是因为这个目录是Docker进程缺省创建出来的。

发现问题之后,相应的解决办法也很简单:把当前目录的拥有者赋值给 uid 1000,再启动jenkins容器就一切正常了。
虽然问题解决了,但思考并没有结束。因为当使用本地数据卷时,jenkins容器会依赖宿主机目录权限的正确性,这会给自动化部署带来额外的工作。如何让jenkins容器为数据卷自动地设置正确的权限?这个问题对很多以non-root方式运行的应用也都有借鉴意义。
为 non-root 应用正确地挂载本地数据卷
基本思路有两个:
- 一个是利用Data Container的方法在容器见共享数据卷。这样就规避了解决宿主机上数据卷的权限问题。由于在1.9版本之后,Docker提供了named volume来取代纯数据容器,所以还需要真正地解决这个问题。
- 另外一个思路就是让容器中进程以root用户启动,在容器启动脚本中利用chown命令来修正数据卷文件权限,之后切换到non-root用户来执行程序。
参照第二个思路来解决之前jenkins的问题。
|
|
这是一个基于jenkins镜像的Dockerfile:它会切换到root用户并在镜像中添加gosu命令,和新的入口点”/entrypoint.sh”。
gosu 是经常出现在官方Docker镜像中的一个小工具。它是su和sudo命令的轻量级替代品,并解决了它们在tty和信号传递中的一些问题。
新入口点的entrypoint.sh内容如下:它会为JENKINS_HOME目录设置jenkins的拥有权限,并且再利用gosu命令切换到jenkins用户来执行jenkins应用。
|
|
Docker Process
Docker在进程管理上有一些特殊之处,如果不注意这些细节就会带来一些隐患。另外Docker鼓励“一个容器一个进程(one process per container)”的方式。这种方式非常适合以单进程为主的微服务架构的应用。然而由于一些传统的应用是由若干紧耦合的多个进程构成的,这些进程难以拆分到不同的容器中,所以在单个容器内运行多个进程便成了一种折衷方案;此外在一些场景中,用户期望利用Docker容器来作为轻量级的虚拟化方案,动态的安装配置应用,这也需要在容器中运行多个进程。而在Docker容器中正确运行多进程应用将会带来更多的挑战。
容器的PID namespace
在Docker中,进程管理的基础就是Linux内核中的PID名空间技术。在不同PID名空间中,进程ID是独立的;即在两个不同名空间下的进程可以有相同的PID。
Linux内核为所有的PID名空间维护了一个树状结构:最顶层的是系统初始化时创建的root namespace(根名空间),再创建的新PID namespace就称之为child namespace(子名空间),而原先的PID名空间就是新创建的PID名空间的parent namespace(父名空间)。通过这种方式,系统中的PID名空间会形成一个层级体系。父节点可以看到子节点中的进程,并可以通过信号等方式对子节点中的进程产生影响。反过来,子节点不能看到父节点名空间中的任何内容,也不可能通过kill或ptrace影响父节点或其他名空间中的进程。
在Docker中,每个Container都是Docker Daemon的子进程,每个Container进程缺省都具有不同的PID命名空间。通过命名空间技术,Docker实现容器间的进程隔离。另外Docker Daemon也会利用PID命名空间的树状结构,实现了对容器中的进程交互、监控和回收。注:Docker还利用了其他命名空间(UTS,IPC,USER)等实现了各种系统资源的隔离。
当创建一个Docker容器的时候,就会新建一个PID命名空间。容器启动进程在该命名空间内PID为1。当PID1进程结束之后,Docker会销毁对应的PID名空间,并向容器内所有其它的子进程发送SIGKILL。
如何指明容器PID1进程
在Docker容器中的初始化进程(PID1进程)在容器进程管理上具有特殊意义。它可以被Dockerfile中的 ENTRYPOINT 或 CMD 所指明;也可以被docker run命令的启动参数所覆盖。了解这些细节可以帮助我们更好地了解PID1进程的行为。
关于ENTRYPOINT和CMD指令的不同,可以参见官方的Dockerfile说明和最佳实践
https://docs.docker.com/engine/reference/builder/#entrypoint
https://docs.docker.com/engine/reference/builder/#cmd
值得注意的一点是:在ENTRYPOINT和CMD指令中,提供两种不同的进程执行方式 shell 和 exec。
在shell方式中,CMD/ENTRYPOINT指令以如下方式定义:
CMD executable param1 param2
这种方式中的PID1进程是以/bin/sh -c “executable param1 param2”方式启动的
CMD ["executable","param1","param2"]
注意这里的可执行命令和参数是利用JSON字符串数组的格式定义的,这样PID1进程会以executable param1 param2方式启动的。另外,在docker run命令中指明的命令行参数也是以 exec 方式启动的。
为了解释两种不同运行方式的区别,我们利用不同的Dockerfile分别创建两个Redis镜像
“Dockerfile_shell”文件内容如下,会利用shell方式启动redis服务
|
|
“Dockerfile_exec”文件内容如下,会利用exec方式启动redis服务
|
|
然后给予他们构建两个镜像“myredis:shell”和“myredis:exec”
|
|
运行”myredis:shell”镜像,我们可以发现它的启动进程(PID1)是/bin/sh -c “/usr/bin/redis-server”,并且它创建了一个子进程/usr/bin/redis-server *:6379。
而运行“myredis:exec”镜像,我们可以发现它的启动进程是/usr/bin/redis-server *:6379,并没有其他子进程存在。
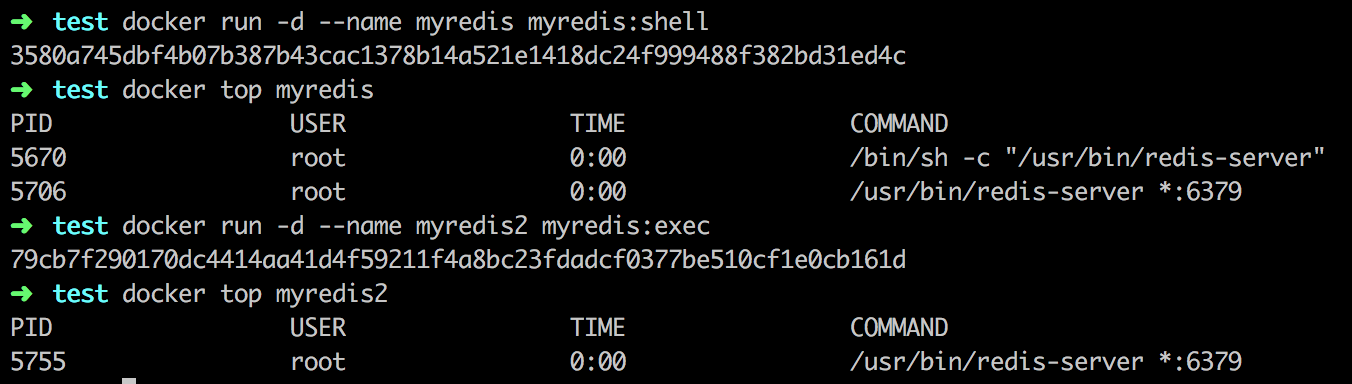
由此我们可以清楚的看到,以exec和shell方式执行命令可能会导致容器的PID1进程不同。然而这又有什么问题呢?
原因在于:PID1进程对于操作系统而言具有特殊意义。操作系统的PID1进程是init进程,以守护进程方式运行,是所有其他进程的祖先,具有完整的进程生命周期管理能力。在Docker容器中,PID1进程是启动进程,它也会负责容器内部进程管理的工作。而这也将导致进程管理在Docker容器内部和完整操作系统上的不同。
进程信号处理
信号是Unix/Linux中进程间异步通信机制。Docker提供了两个命令docker stop和docker kill来向容器中的PID1进程发送信号。
当执行docker stop命令时,docker会首先向容器的PID1进程发送一个SIGTERM信号,用于容器内程序的退出。如果容器在收到SIGTERM后没有结束, 那么Docker Daemon会在等待一段时间(默认是10s)后,再向容器发送SIGKILL信号,将容器杀死变为退出状态。这种方式给Docker应用提供了一个优雅的退出(graceful stop)机制,允许应用在收到stop命令时清理和释放使用中的资源。而docker kill可以向容器内PID1进程发送任何信号,缺省是发送SIGKILL信号来强制退出应用。
从Docker 1.9开始,Docker支持停止容器时向其发送自定义信号,开发者可以在Dockerfile使用STOPSIGNAL指令,或docker run命令中使用–stop-signal参数中指明,缺省是SIGTERM。
我们来看看不同的PID1进程,对进程信号处理的不同之处。首先,我们使用docker stop命令停止由 exec 模式启动的“myredis2”容器,并检查其日志。
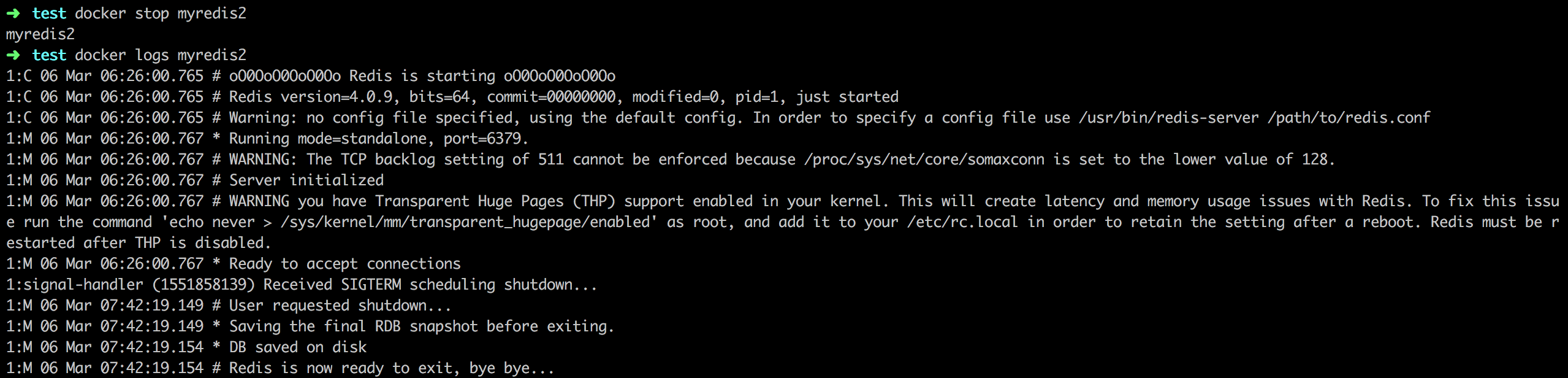
我们发现对“myredis2”容器的stop命令几乎立即生效;而且在容器日志中,我们看到了“Received SIGTERM scheduling shutdown”的内容,说明redis-server进程接收到了SIGTERM消息,并优雅地推出。
我们再对利用shell模式启动的“myredis”容器发出停止操作,并检查其日志。

我们发现对”myredis”容器的stop命令暂停了一会儿才结束,而且在日志中我们没有看到任何收到SIGTERM信号的内容。原因其PID1进程sh没有对SIGTERM信号的处理逻辑,所以它忽略了所接收到的SIGTERM信号。当Docker等待stop命令执行10秒钟超时之后,Docker Daemon发送SIGKILL强制杀死sh进程,并销毁了它的PID名空间,其子进程redis-server也在收到SIGKILL信号后被强制终止。如果此时应用还有正在执行的事务或未持久化的数据,强制进程退出可能导致数据丢失或状态不一致。
通过这个示例我们可以清楚的理解PID1进程在信号管理的重要作用。所以,
- 容器的PID1进程需要能够正确的处理SIGTERM信号来支持优雅退出。
- 如果容器中包含多个进程,需要PID1进程能够正确的传播SIGTERM信号来结束所有的子进程之后再推出。
- 确保PID1进程是期望的进程。缺省sh/bash进程没有提供SIGTERM的处理,需要通过shell的脚本来设置正确的PID1进程,或捕获SIGTERM信号。
另外需要注意的是:由于PID1进程的特殊性,Linux内核为他做了特殊处理。如果它没有提供某个信号的处理逻辑,那么与其在同一个PID命名空间下的进程发送给它的该信号都会被屏蔽。这个功能的主要作用是防止init进程被误杀。我们可以验证在容器内部发出的SIGKILL信号无法杀死PID1进程.
孤儿进程与僵尸进程管理
熟悉Unix/Linux进程管理的同学对多进程应用并不陌生。
当一个子进程终止后,它首先会变成一个“失效(defunct)”的进程,也称为“僵尸(zombie)”进程,等待父进程或系统收回(reap)。在Linux内核中维护了关于“僵尸”进程的一组信息(PID,终止状态,资源使用信息),从而允许父进程能够获取有关子进程的信息。如果不能正确回收“僵尸”进程,那么他们的进程描述符仍然保存在系统中,系统资源会缓慢泄露。
大多数设计良好的多进程应用可以正确的收回僵尸子进程,比如NGINX master进程可以收回已终止的worker子进程。如果需要自己实现,则可利用如下方法:
- 利用操作系统的waitpid()函数等待子进程结束并清除它的僵尸进程。
- 由于当子进程成为“defunct”进程时,父进程会收到一个SIGCHLD信号,所以我们可以在父进程中指定信号处理的函数来忽略SIGCHLD信号,或者自定义收回处理逻辑。
下面这些文章详细介绍了对僵尸进程的处理方法
- http://www.microhowto.info/howto/reap_zombie_processes_using_a_sigchld_handler.html
- http://lbolla.info/blog/2014/01/23/die-zombie-die
如果父进程已经结束了,那些依然在运行中的子进程会成为“孤儿(orphaned)”进程。在Linux中Init进程(PID1)作为所有进程的父进程,会维护进程树的状态,一旦有某个子进程成为了“孤儿”进程后,init就会负责接管这个子进程。当一个子进程成为“僵尸”进程之后,如果其父进程已经结束,init会收割这些“僵尸”,释放PID资源。
然而由于Docker容器的PID1进程是容器启动进程,它们会如何处理那些“孤儿”进程和“僵尸”进程?
下面我们做几个试验来验证不同的PID1进程对僵尸进程不同的处理能力
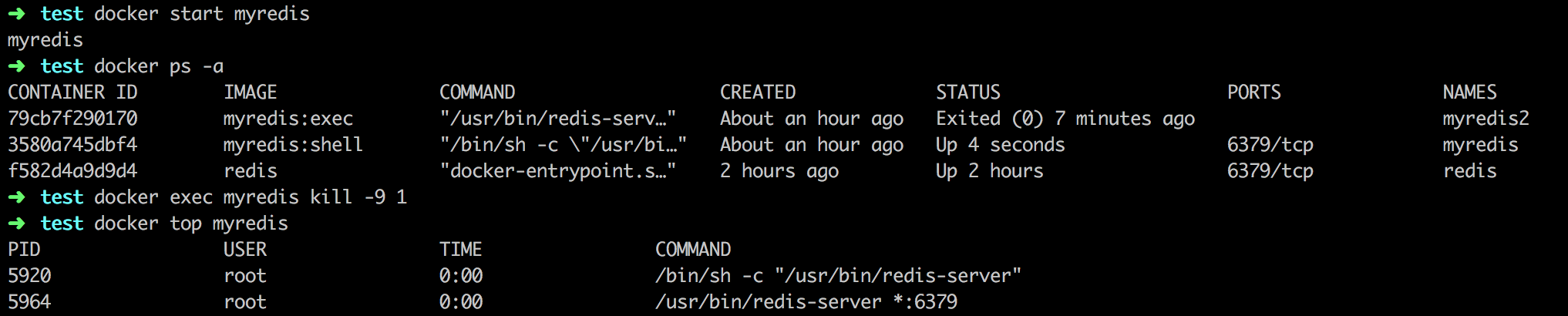
首先在myredis2容器中启动一个bash进程,并创建子进程“sleep 1000”
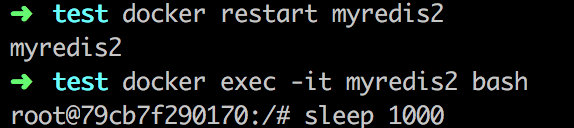
在另一个终端窗口,查看当前进程,我们可以发现一个sleep进程是bash进程的子进程。

我们杀死bash进程之后查看进程列表,这时候bash进程已经被杀死。这时候sleep进程(PID为49),虽然已经结束,而且被PID1进程(redis-server)接管,但是其没有被父进程回收,成为僵尸状态。
这是因为PID1进程“redis-server”没有考虑过作为init对僵尸子进程的回收的场景。
同样的实验对myredis容器测试,发现“bash”和“sleep 1000”进程都已经被杀死和回收。这是因为sh/bash等应用可以自动清理僵尸进程。
如果在容器中运行多个进程,PID1进程需要有能力接管“孤儿”进程并回收“僵尸”进程。Docker从1.13版本开始提供了 docker run –init 参数,可以运行一个init来启动容器,并且提供信号传播和进程回收的作用。
进程监控
在Docker中,如果docker run命令中指明了restart policy,Docker daemon会监控PID1进程,并根据策略自动重启已结束的容器。
| Flannel | |
|---|---|
| no | 不自动重启,缺省值。 |
| on-failure[:max-retries] | 当PID1进程退出值非0时,自动重启容器;可以指定最大重试次数。 |
| always | 永远自动重启容器;当Docker daemon启东市,会自动启动容器。 |
| unless-stopped | 永远自动重启容器;当Docker daemon启动时,如果之前容器不为stoped状态就自动启动容器。 |
注意:为防止频繁重启故障应用导致系统过载,Docker会在每次重启过程中会延迟一段时间。Docker重启进程的延迟时间从100ms开始并每次加倍,如100ms,200ms,400ms等等。
利用Docker内置的restart策略可以大大简化应用进程监控的负担。但是Docker Daemon只是监控PID1进程,如果容器在内包含多个进程,仍然需要开发人员来处理进程监控。
还有大家熟悉的Supervisor,Monit等进程监控工具,它们可以方便的在容器内部实现进程监控。Docker提供了相应的文档来介绍,网上也有很多资料。
另外利用Supervisor等工具作为PID1进程是在容器中支持多进程管理的主要实现方式;和简单利用shell脚本fork子进程相比,采用Supervisor等工具有很多好处:
- 一些传统的服务不能以PID1进程的方式执行,利用Supervisor可以方便的适配
- Supervisor这些监控工具大多提供了对SIGTERM的信号传播支持,可以支持子进程优雅的退出。
然而值得注意的是:Supervisor这些监控工具大多没有完全提供Init支持的进程管理能力,如果需要支持子进程回收的场景需要配合正确的PID1进程来完成
总结
进程管理在Docker容器中和在完整的操作系统有一些不同之处。在每个容器的PID1进程,需要能够正确的处理SIGTERM信号来支持容器应用的优雅退出,同时要能正确的处理孤儿进程和僵尸进程。必要的时候使用Docker新提供的 docker run –init 参数可以解决相应问题。
在Dockerfile中要注意shell模式和exec模式的不同。通常而言我们鼓励使用exec模式,这样可以避免由无意中选择错误PID1进程所引入的问题。
在Docker中“一个容器一个进程的方式”并非绝对化的要求,然而在一个容器中实现对于多个进程的管理必须考虑更多的细节,比如子进程管理,进程监控等等。所以对于常见的需求,比如日志收集,性能监控,调试程序,我们依然建议采用多个容器组装的方式来实现。
Docker security
主要从四块区域思考Docker安全:
- Linux内核层面的安全:namespace和cgroups
- Docker daemon的攻击面
- 容器配置时的漏洞
- 内核的安全强化功能,以及如何它们如何与容器交互