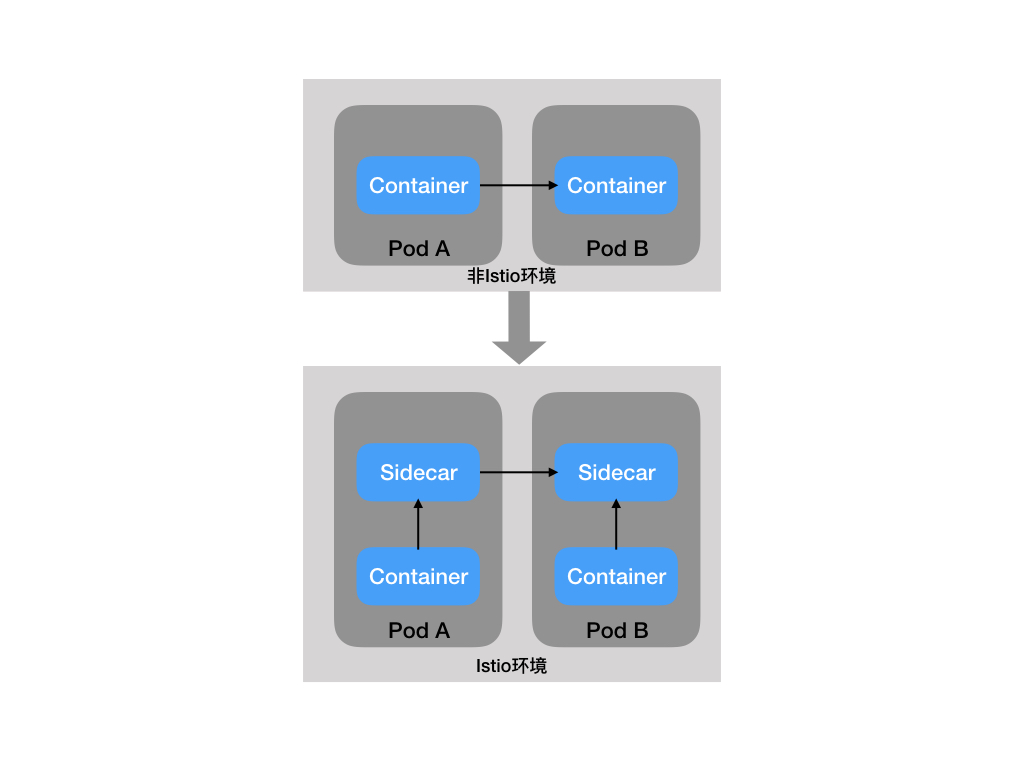
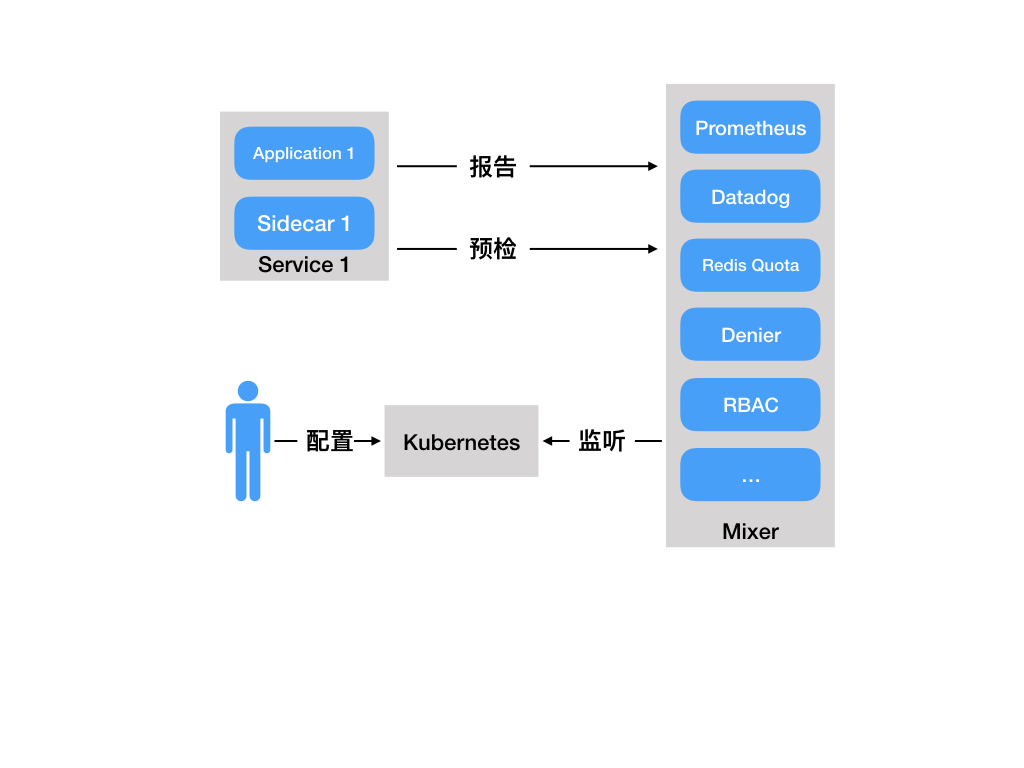
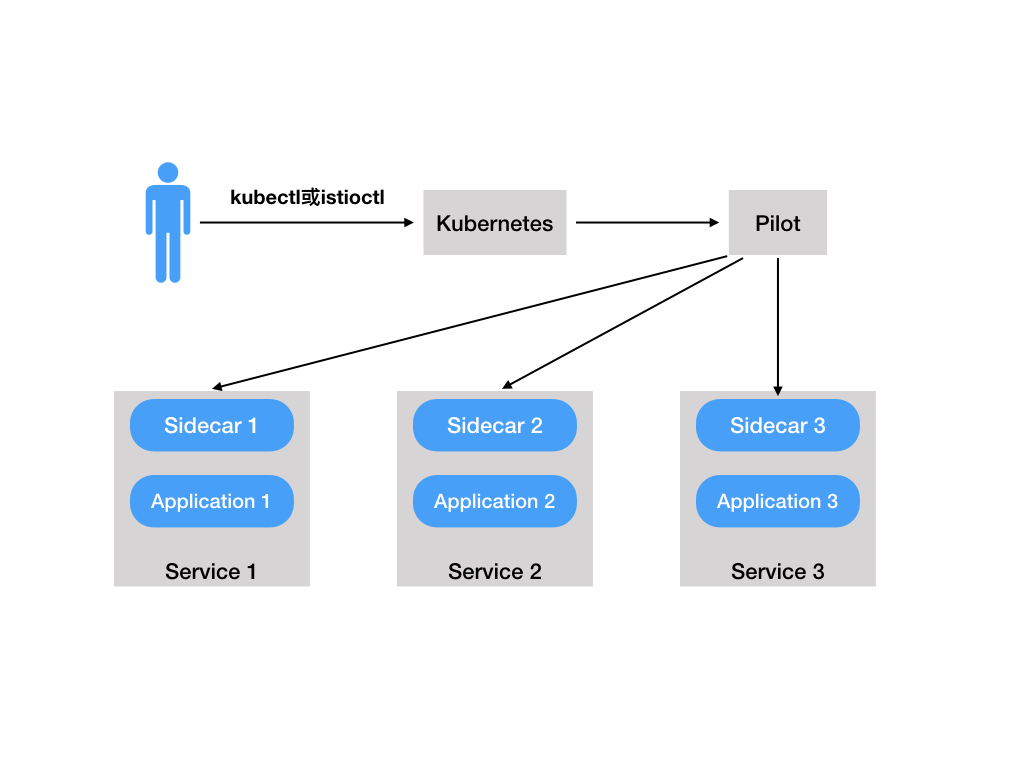
策略一致性:在服务间的 API 调用中,策略的应用使得可以对网格间行为进行全面的控制,但对于无需在 API 级别表达的资源来说,对资源应用策略也同样重要。例如,将配额应用到 ML 训练任务消耗的 CPU 数量上,比将配额应用到启动这个工作的调用上更为有用。因此,策略系统作为独特的服务来维护,具有自己的 API,而不是将其放到代理/sidecar 中,这容许服务根据需要直接与其集成。
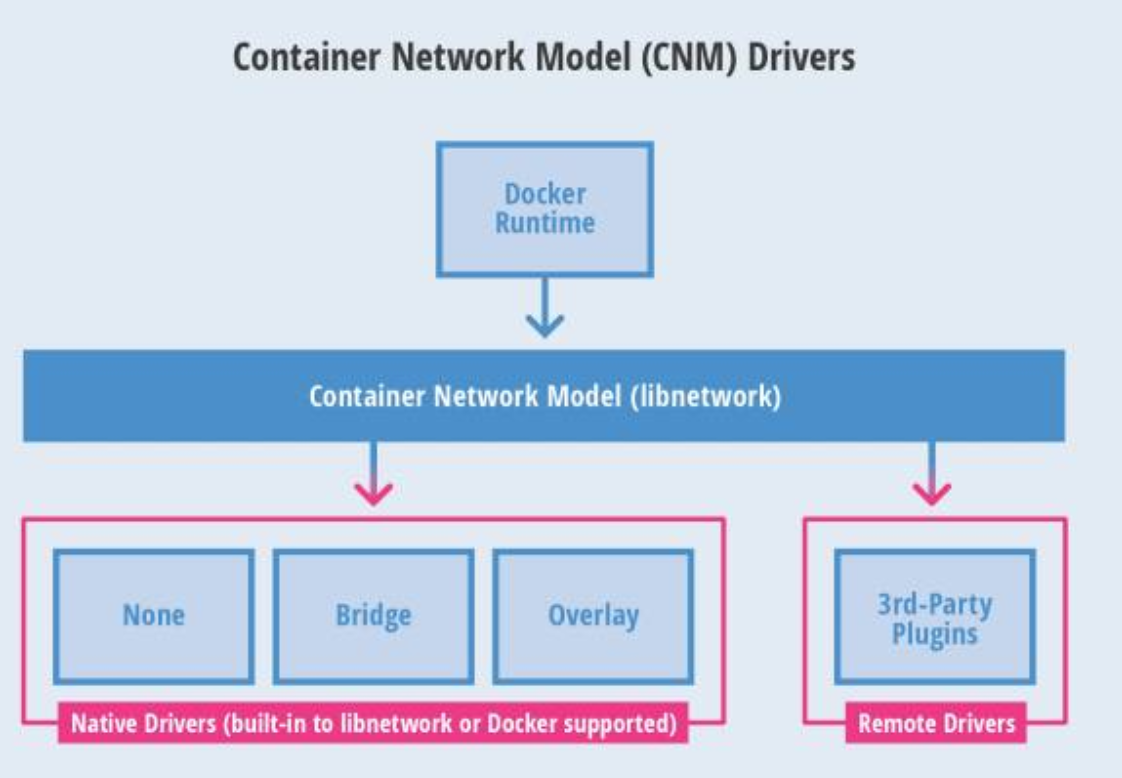
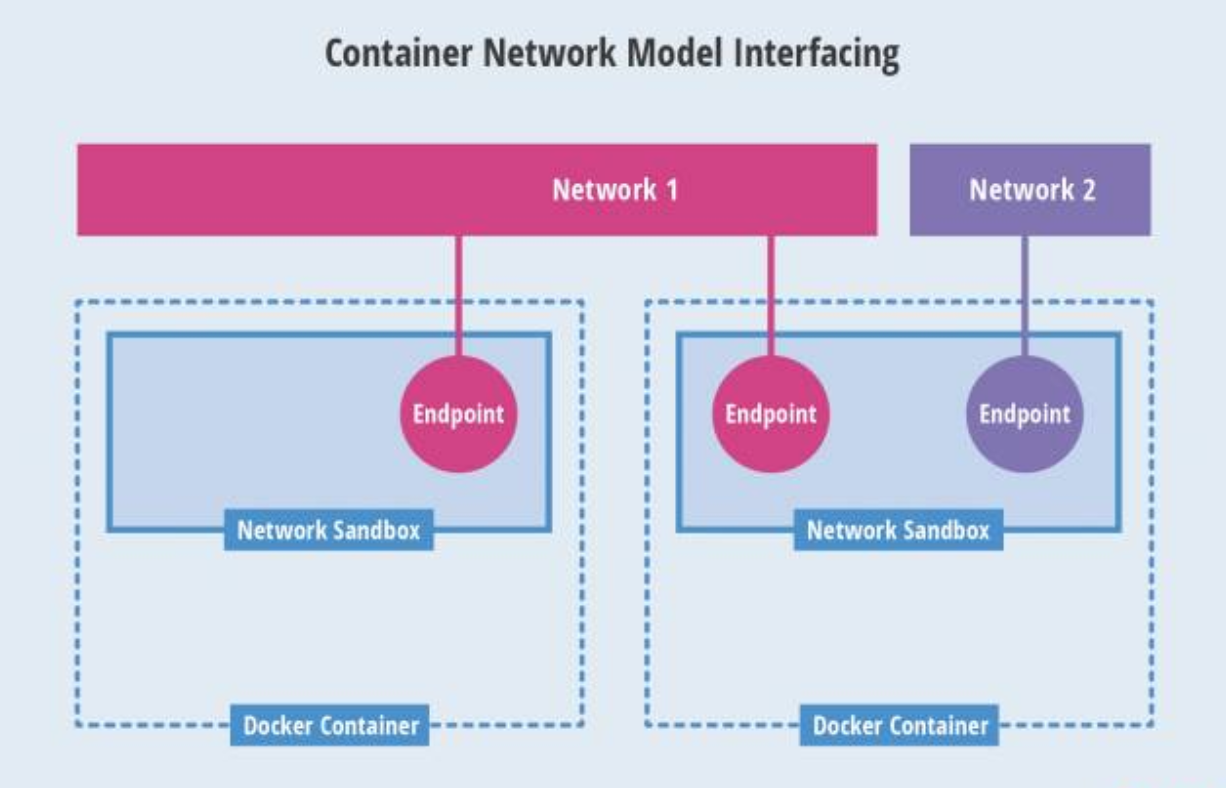
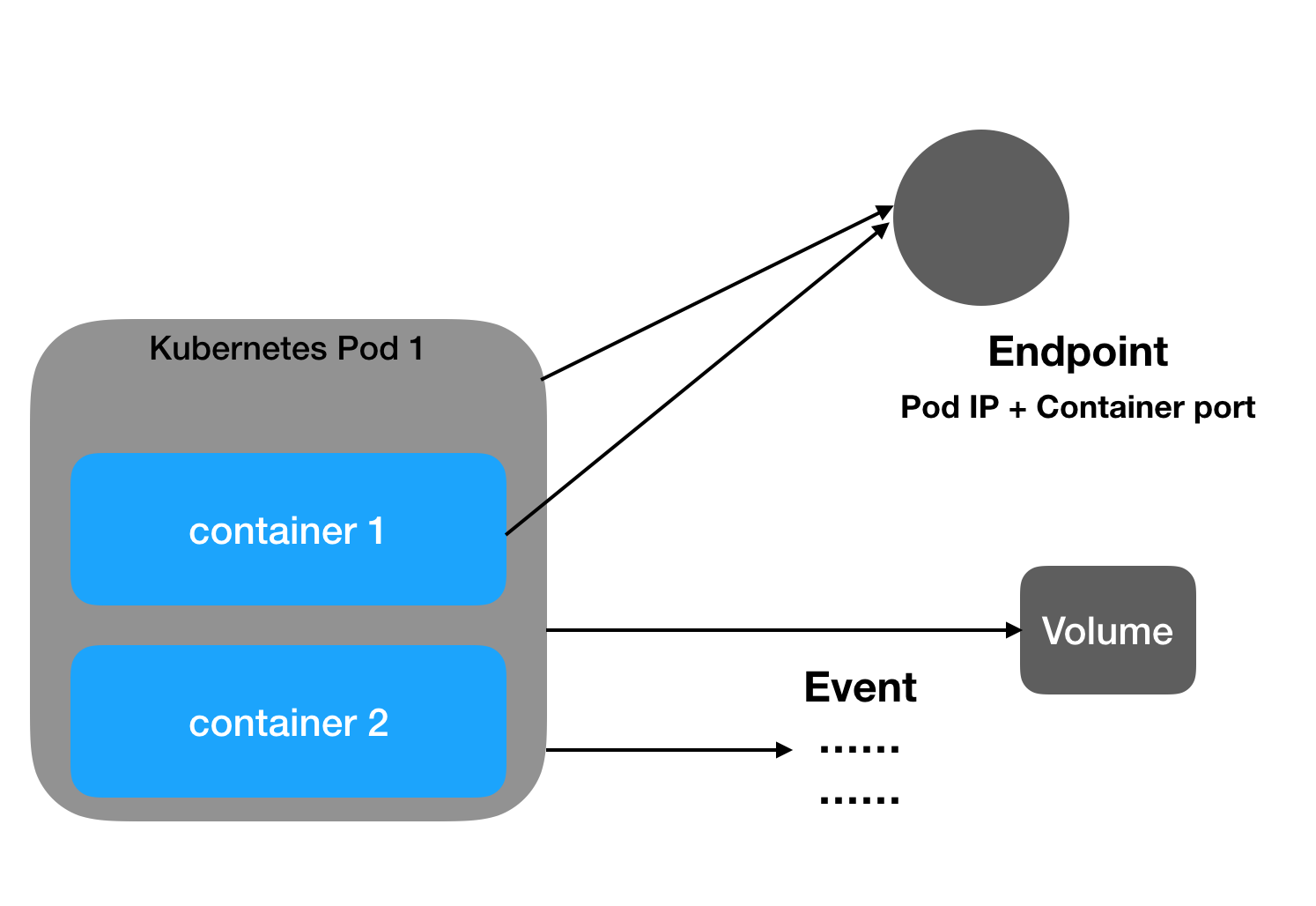
Kubernetes 为每个 Pod 都分配了唯一的 IP 地址,称之为 PodIP,一个 Pod 里的多个容器共享 PodIP 地址。Pod 的 IP 加上 Pod 里的容器端口(containerPort),就组成了一个概念————Endpoint,它代表此 Pod 里的一个服务进程的对外通信地址。一个 Pod 也存在着具有多个 Endpoint 的情况。
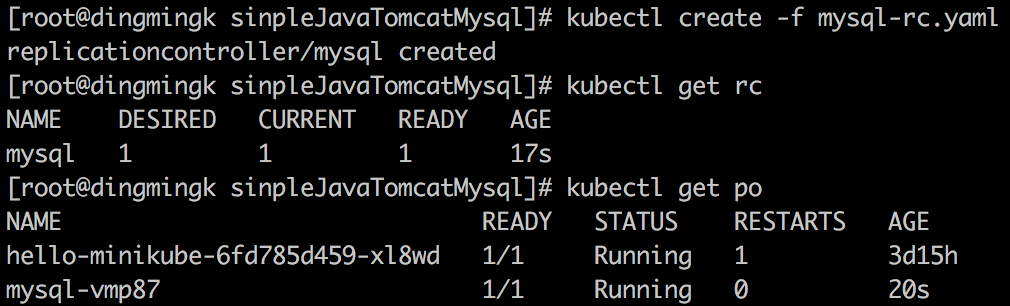
当我们定义了一个 RC 并提交到 Kubernetes 集群中以后,Master 节点上的 Controller Manager 组件就得到通知,定期巡检系统中当前存活的目标 Pod,并确保目标 Pod 实例的数量刚好等于此 RC 的期望值,如果有过多的 Pod 副本在运行,系统就会停掉一些 Pod,否则系统就会再自动创建一些 Pod。通过 RC,Kubernetes 实现了用户应用集群的高可用性,并且大大减少了系统管理员在传统 IT 环境中需要完成的许多手工运维工作(如主机监控脚本、应用监控脚本、故障恢复脚本等)。
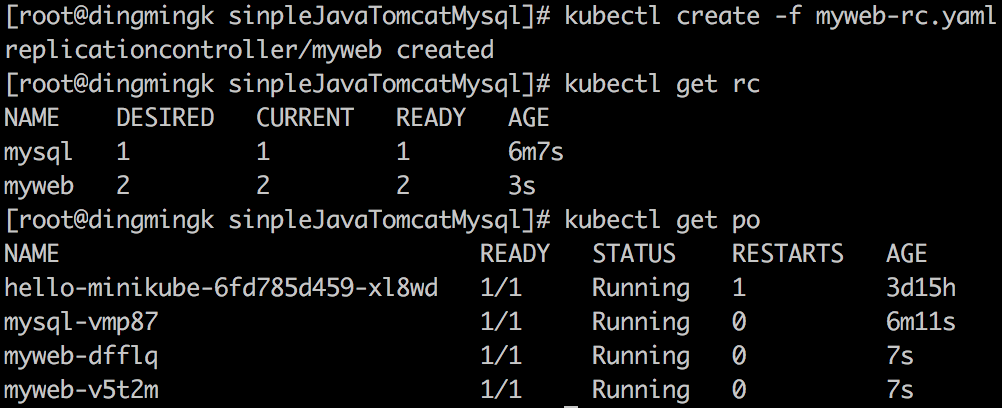
在 RC 运行时,我们可以通过修改 RC 的副本数量,来实现 Pod 的动态缩放(Scaling)功能:
kubect scale rc frontend --replicas=3
在 Kubernetes v1.2时,Replication Controller升级成了 Replica Set,新功能支持集合的 Label selector(Set-based selector)。不过一般很少单独使用Replica Set,它主要被 Deployment 这个更高层的资源对象所使用,从而形成一整套 Pod 创建、删除、更新的编排机制。下面是等价于前面 RC 例子的 Replica Set 的定义(省去了 Pod 模版部分的内容):
1
2
3
4
5
6
7
8
9
10
11
12
apiVersion: extensions/v1beta1
kind: ReplicaSet
metadata:
name: frontend
spec:
selector:
matchLabels:
tier: frontend
matchExpressions:
- {key: tier, operator: In, values: [frontend]}
template:
......
最后我们总结一下关于 RC(Replica Set)的一些特性与作用:
在大多数情况下,我们通过定义一个 RC 实现 Pod 的创建过程及副本数量的自动控制。
RC 里包括完整的 Pod 定义模版。
RC 通过 Label Selector 机制实现对 Pod 副本的自动控制。
通过改变 RC 里的 Pod 副本数量,可以实现 Pod 的扩容或缩容功能。
通过改变 RC 里 Pod 模版中的镜像版本,可以实现 Pod 的滚动升级功能。
Deployment
Deployment 是 Kubernetes v1.2 引入的新概念,引入的目的是为了更好地解决 Pod 的编排问题。为此,Deployment 在内部使用了 Replica Set 来实现目的,无论从 Deployment 的作用与目的、它的 YAML 定义,还是从它的具体命令行操作来看,我们都可以把它看作 RC 的一次升级,两者的相似度超过 90%。
Deployment 相对于 RC 的一个最大升级是可以随时知道当前 Pod “部署” 的进度。实际上由于一个 Pod 的创建、调度、绑定节点及在目标 Node 上启动对应的容器这一完整过程需要一定的时间,所以我们期待系统启动 N 个 Pod 副本的目标状态,实际上是一个连续变化的“部署过程”导致的最终状态。
Deployment 的典型使用场景有以下几个:
创建一个 Deployment 对象来生成对应的 Replica Set 并完成 Pod 副本的创建过程。
UP-TO-DATE: 最新版本的 Pod 的副本数量,用于指示在滚动升级的过程中,有多少个副本已经成功升级。
AVAILABLE: 当前集群中可用的 Pod 副本数量,即集群中当前存活的 Pod 数量。
查看 Replica Set,可以看到它的命名与 Deployment 的名字有关系:
kubectl get rs
查看创建的 Pod,我嗯发现 Pod 的命名以 Deployment 对应的 Replica Set 的名字为前缀,这种命名很清晰地表明了一个 Replica Set 创建了哪些 Pod,对于 Pod 滚动升级这种复杂的过程来说,很容易排查错误:
kubectl get pods
Pod 的管理对象,除了 RC 和 Deployment,还包括 ReplicaSet、DaemonSet、StatefulSet、Job 等,分别用于不同的应用场景中。
Horizontal Pod Autoscaler
前面我们提到过,通过手动执行 kubectl scale 命令,可以实现 Pod 扩容或缩容。而 Kubernetes v1.1 版本中发布了一个新特性————Horizontal Pod Autoscaling(Pod 横向自动扩容,简称 HPA)。
HPA 与之前的 RC、Deployment 一样,也属于一种 Kubernetes 资源对象。通过追踪分析 RC 控制的所有目标 Pod 的负载变化情况,来确定是否需要针对性地调整目标 Pod 的副本数。当前,HPA 可以有以下两种方式作为 Pod 负载的度量指标:
CPUUtilizationPercentage
应用程序自定义的度量指标,比如服务在每秒内的相应的请求数(TPS 或 QPS)。
CPUUtilizationPercentage 是一个算数平均值,即目标 Pod 所有副本自身的 CPU 利用率的平均值。一个 Pod 自身的 CPU 利用率是该 Pod 当前 CPU 的使用量除以它的 Pod Request 的值,比如我们定义一个 Pod 的 Pod Request 为 0.4,而当前 Pod 的 CPU 使用量为 0.2,则它的 CPU 使用率为50%,如此一来,我们就可以算出一个 RC 控制的所有 Pod 副本的 CPU 利用率的算术平均值了。如果某一时刻 CPUUtilizationPercentage 的值超过 80%,则意味着当前的 Pod 副本数很可能不足以支撑接下来更多的请求,需要进行动态扩容,而当请求高峰时段过去后, Pod 的 CPU 利用率又会降下来,此时对应的 Pod 副本数应该自动减少到一个合理的水平。
如果用 RC/Deployment 控制 Pod 副本数的方式来实现上述有状态的集群,我们会发现第 1 点是无法满足的,因为 Pod 的名字是随机产生的,Pod 的 IP 地址也是在运行期才确定且可能有变动的,我们实现无法为每个 Pod 确定唯一不变的 ID。另外,为了能够在其他节点上恢复某个失败的节点,这种集群中的 Pod 需要挂接某种共享存储,为了解决这个问题,Kubernetes 从 v1.4 版本开始引入了 PetSet 这个新的资源对象,并且在 v1.5 版本是更名为 StatefulSet,StatefulSet 从本质上来说,可以看作 Deployment/RC 的一个特殊变种,它有如下一些特性:
StatefulSet 里的每个 Pod 都有稳定、唯一的网络标识,可以用来发现集群内的其他成员。假设 StatefulSet 的名字叫 kafka,那么第一个 Pod 叫 kafka-0,第二个叫 kafka-1,以此类推。
StatefulSet 控制的 Pod 副本的启停顺序是受控的,操作第 n 个 Pod 时,前 n-1 个 Pod 已经是运行且准备好的状态。
StatefulSet 里的 Pod 采用稳定的持久化存储卷,通过 PV/PVC 来实现,删除 Pod 时默认不会删除与 StatefulSet 相关的存储卷(为了保证数据的安全)。
StatefulSet 除了要与 PV 卷捆绑使用以存储 Pod 的状态数据,还要与 Headless Service 配合使用,即在每个 StatefulSet 的定义中要声明它属于哪个 Headless Service。Headless Service 与普通 Service 的关键区别在于,它没有 Cluster IP,如果解析 Headless Service 的 DNS 域名,则返回的是该 Service 对应的全部 Pod 的 Endpoint 列表。StatefulSet 在 Headless Service 的基础上又为 StatefulSet 控制的每个 Pod 实例创建了一个 DNS 域名,这个域名的格式为:$(podname).$(headless service name)。
比如一个 3 节点的 Kafka 的 StatefulSet 集群对应的 Headless Service 的名字为 kafka,则 StatefulSet 里面的 3 个 Pod 的 DNS 名称分别为 kafka-0.kafka、kafka-1.kafka、kafka-2.kafka,这些 DNS 名称可以直接在集群的配置文件中固定下来。
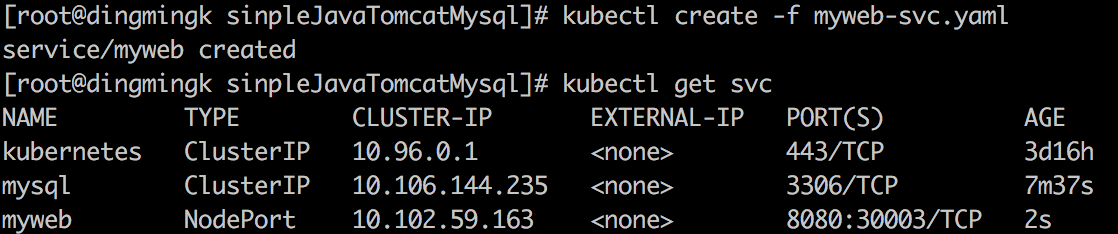
Service
Service 也是 Kubernetes 里的最核心的资源对象之一,Kubernetes 里的每个 Service 其实就是我们经常提起的微服务架构中的一个“微服务”,之前提到的 Pod、RC 等资源对象都是为它服务的。
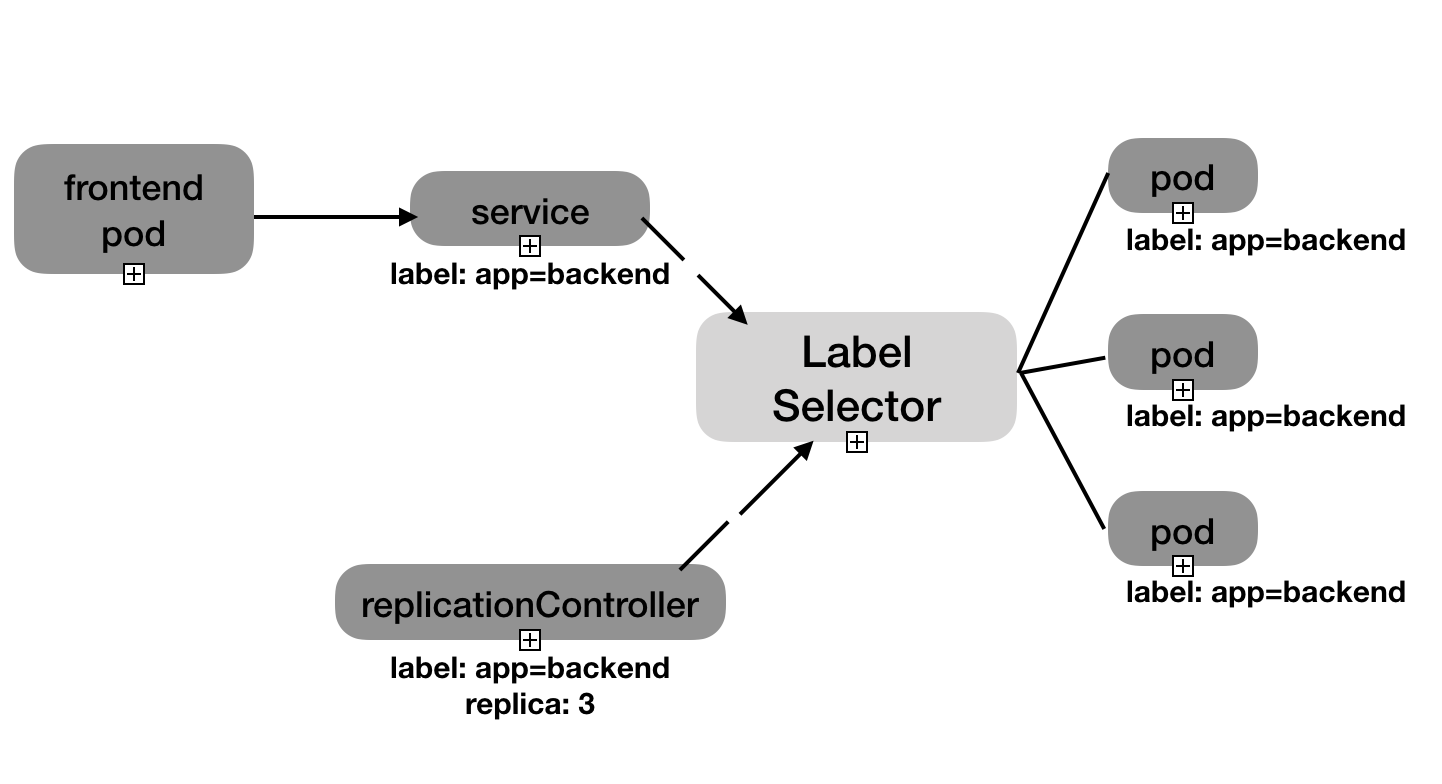
从图中可以看到,Kubernetes 的 Service 定义了一个服务的访问入口地址,前端的应用(Pod)通过这个入口地址访问其背后的一组由 Pod 副本组成的集群实例,Service 与其后端 Pod 副本集群之间则是通过 Label Selector 来实现“无缝对接”的。而 RC 的作用实际上是保证 Service 的服务能力和服务质量始终处于预期的标准。
Kubernetes集群中,运行在每个 Node 上的 kube-proxy 进程其实就是一个智能的软件负载均衡器,它负责把对 Service 的请求转发到后端的某个 Pod 实例上,并在内部实现服务的负载均衡与会话保持机制。但 Service 不是共用一个负载均衡器的 IP 地址,而是每个 Service 分配了一个全局唯一的虚拟 IP 地址,这个虚拟 IP 被称为 ClusterIP。这样一来,每个服务就变成了具备唯一 IP 地址的“通信节点”,服务调用就变成了最基础的 TCP 网络通信问题。
我们知道,Pod 的 Endpoint 地址会随着 Pod 的销毁和重新创建而发生改变,因为新 Pod 的 IP 地址与之前旧 Pod 的不同。而 Service 一旦被创建,Kubernetes 就会自动为它分配一个可用的 Cluster IP,而且在 Service 的整个生命周期内,它的 Cluster IP 不会发生改变。于是,服务发现这个棘手的问题在 Kubernetes的架构里也得以轻松解决:只要用 Service 的 Name 与 Service 的 Cluster IP 地址做一个 DNS 域名映射即可完美解决问题。
Volume
Volume 是 Pod 中能够被多个容器访问的共享目录。Kubernetes 的 Volume 概念、用途和目的与 Docker 的 Volume 比较类似,但两者不能等价。首先,Kubernetes 中的 Volume 定义在 Pod 上,然后被一个 Pod 里的多个容器挂载到具体的文件目录下;其次,Kubernetes中的 Volume 与 Pod 的生命周期相同,但与容器的生命周期不相关,当容器终止或者重启时,Volume 中的数据也不会丢失。最后,Kubernetes 支持多种类型的 Volume,例如 GlusterFS、Ceph 等先进的分布式文件系统。
Volume 的使用也比较简单,在大多数情况下,我们先在 Pod 上声明一个 Volume,然后在容器里引用该 Volume 并 Mount 到容器里的某个目录上。比如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
......
template:
metadata:
labels:
app: app-demo
tier: frontend
spec:
volumes:
- name: datavol
emptyDir: {}
containers:
- name: tomcat-demo
image: tomcat
volumeMounts:
- mountPath: /mydata-data
name: datavol
imagePullPolicy: IfNotPresent
......
除了可以让一个 Pod 里的多个容器共享文件、让容器的数据写到宿主机的磁盘上或者写文件到网络存储中,Kubernetes 的 Volume 还扩展出了一种非常有实用价值的功能,即容器配置文件集中化定义与管理,这是通过 ConfigMap 这个资源对象来实现的。
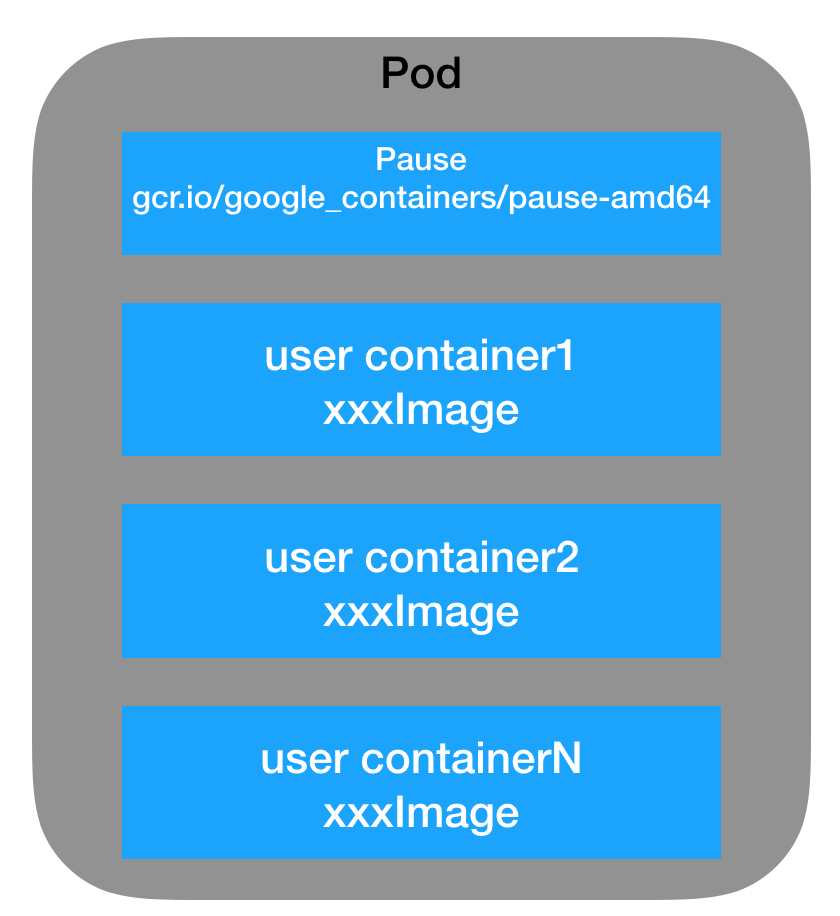
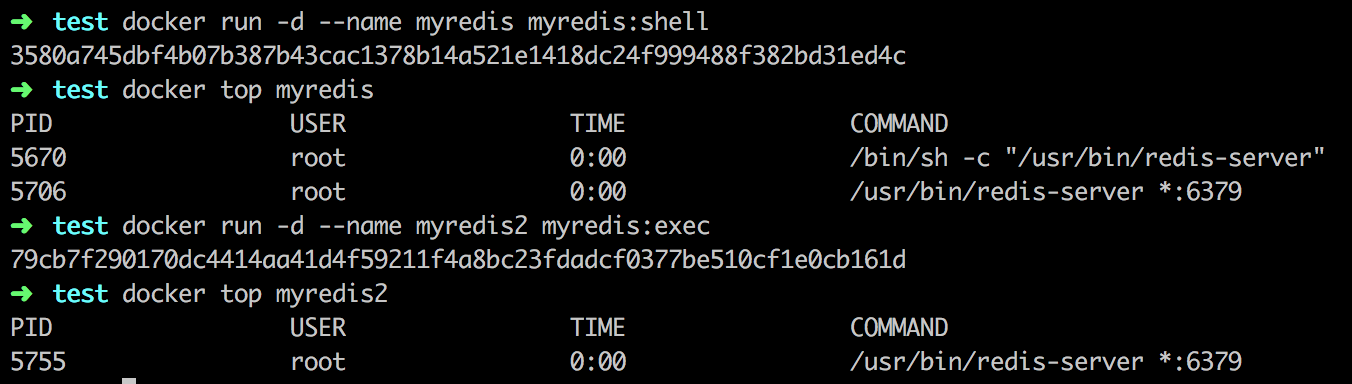
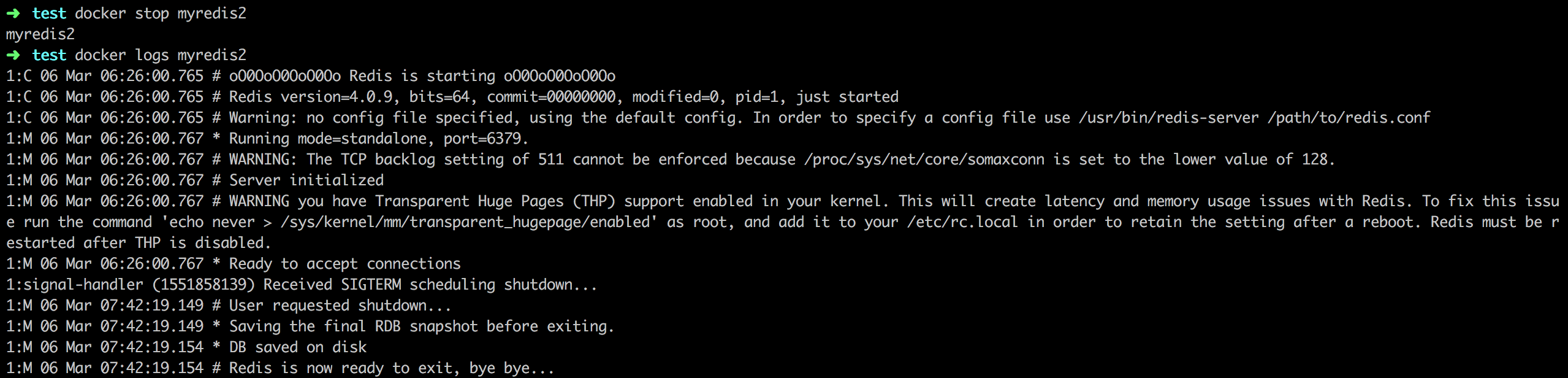
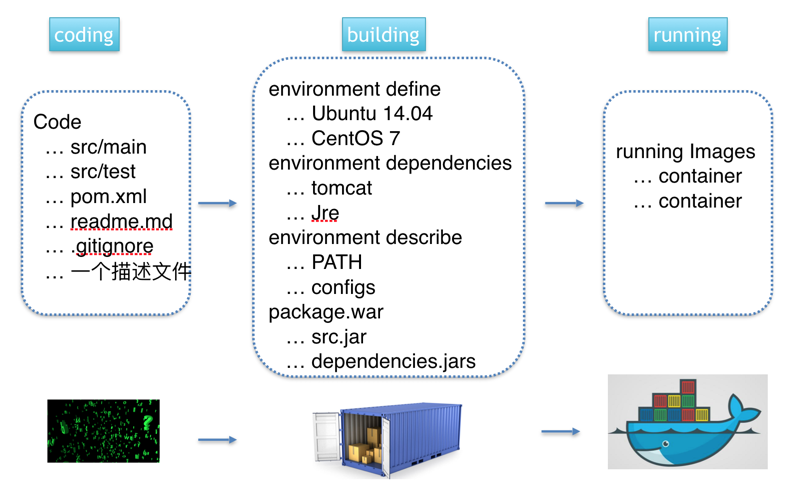
Docker在进程管理上有一些特殊之处,如果不注意这些细节就会带来一些隐患。另外Docker鼓励“一个容器一个进程(one process per container)”的方式。这种方式非常适合以单进程为主的微服务架构的应用。然而由于一些传统的应用是由若干紧耦合的多个进程构成的,这些进程难以拆分到不同的容器中,所以在单个容器内运行多个进程便成了一种折衷方案;此外在一些场景中,用户期望利用Docker容器来作为轻量级的虚拟化方案,动态的安装配置应用,这也需要在容器中运行多个进程。而在Docker容器中正确运行多进程应用将会带来更多的挑战。
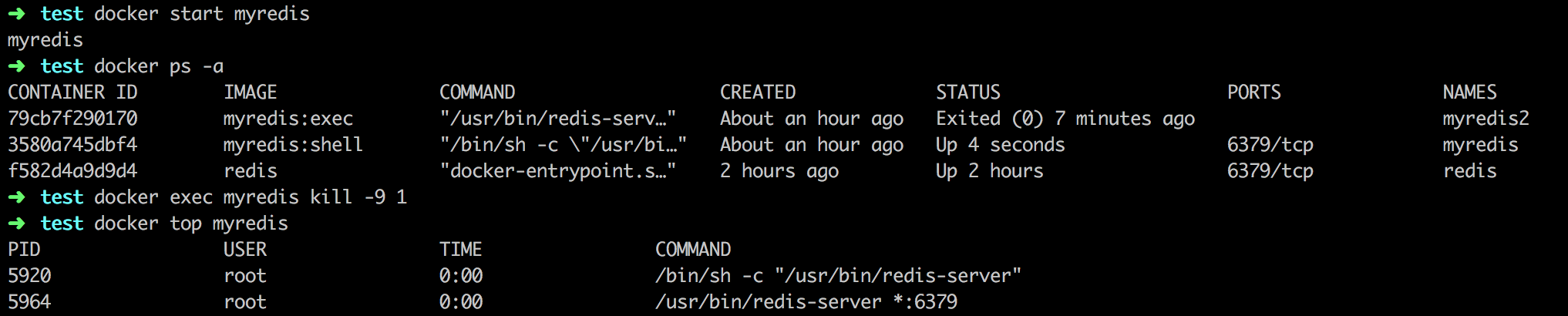
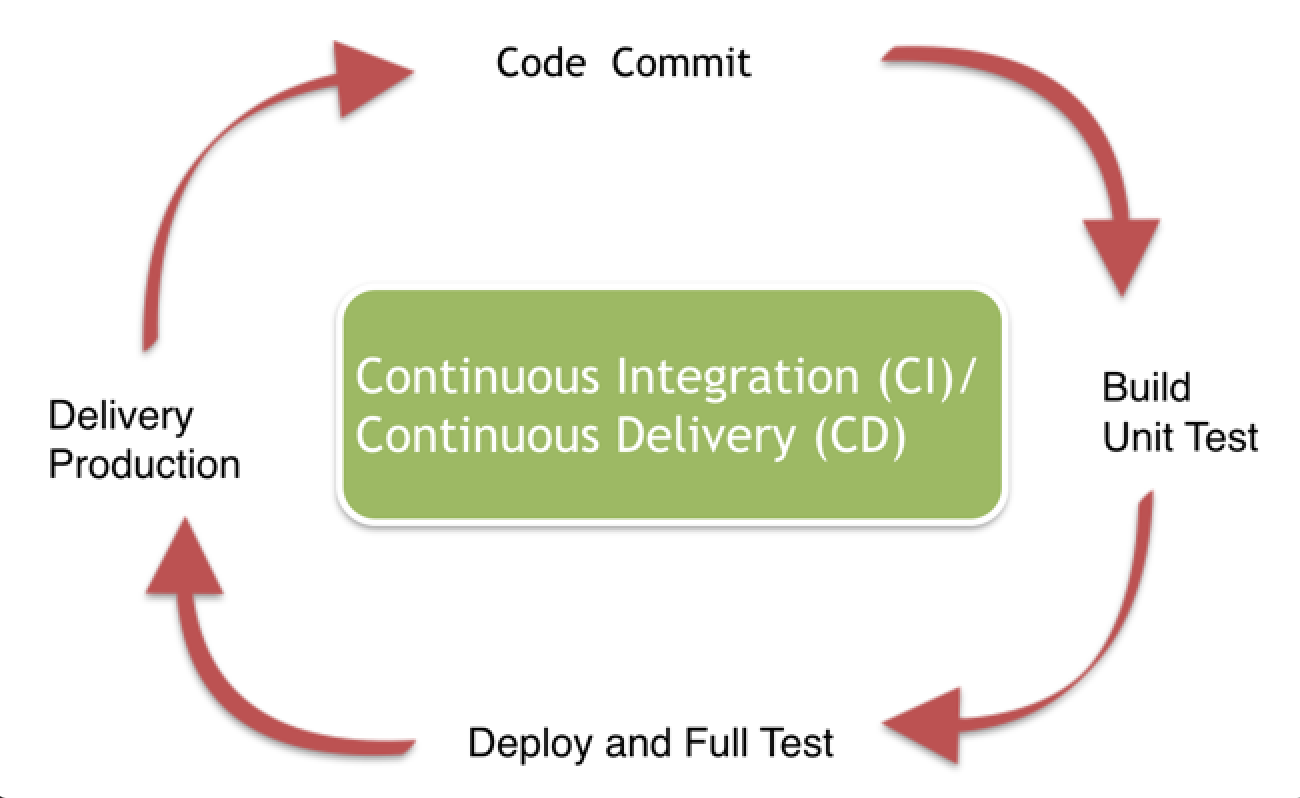
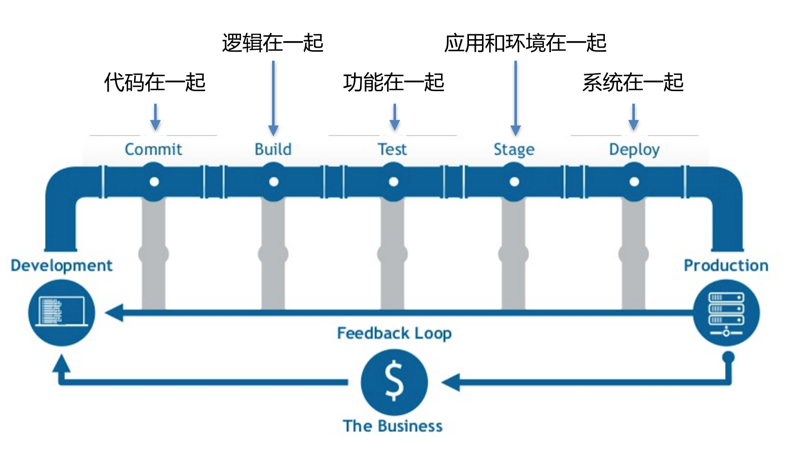
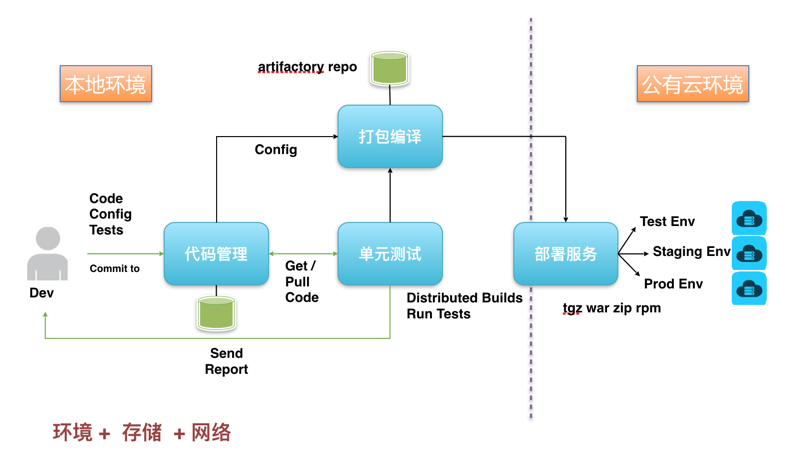
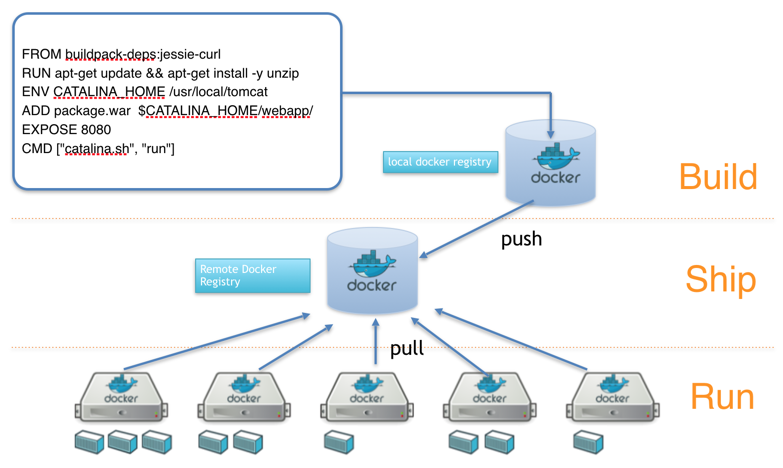
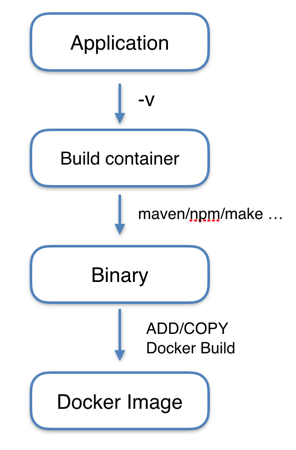
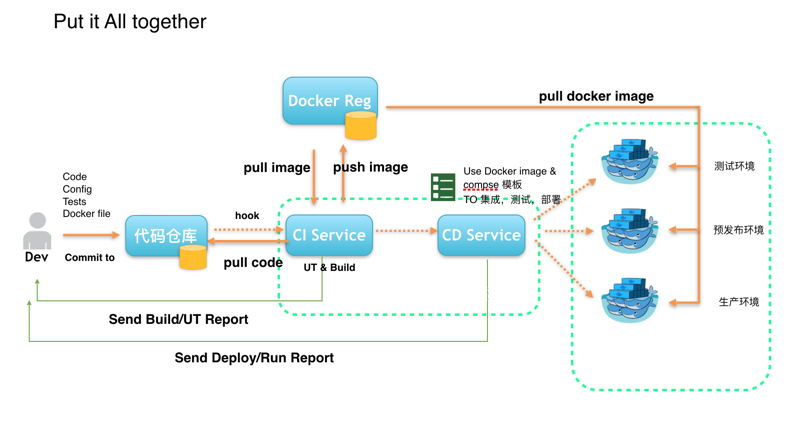
当build test 都pass之后, 通过deploy service 告诉应用集群进行更新,从docker registry 上pull 下来新的image进行应用更新,或更新集群配置
用docker 为开发/运维人员带来的好处
Docker技术是 DevOps 的最好诠释, DevOps不是开发去做运维的事情, 而是:
将编程的思想应用到运维领域
举例来说: Immutable,Copy on Write 这些思想在研发领域是耳熟能详的,好处大家秒懂。而在运维领域的Immutable,传统是怎么做的? 靠组织架构,权限管理。各种人为订制的机制,规范。 而docker 是用技术来解决了这个问题, 官方文档的介绍docker是 An open platform for distributed applications for developers and sysadmins, 很明显看到了DevOps有木有?